Things I wished I knew when building an authentication system (Part 1)
Building an authentication allows users to log in. Most people go with OAuth2 or Identity Service Providers. But what if I want to create my own?
Building an authentication allows users who use your application to log in. Like most other people, I do some research on Authentication and found out that most approaches involve using one of the identities as a service (IDaaS) providers or third-party OAuth2.0.
I am going to talk briefly about the alternatives above, but if you come here just for the cake, feel free to skip the following section.
This blog post only talks generally about the Authentication system without going into any particular implementation. If you want to read about one that does, I wrote How I build my authentication system with Next.js and MongoDB in 2019.
Please be aware that SQL and NoSQL are broad terms. Not every SQL or NoSQL server is the same, and the information in this article may not apply to every database.
Identity providers and third-party OAuth2
IDaaS providers are those who provide a cloud-based infrastructure that does the job for you. They often offer out-of-the-box implementation for most frameworks and platforms. Azure Active Directory (Microsoft) is one of the examples of IDaaS. See the image below.

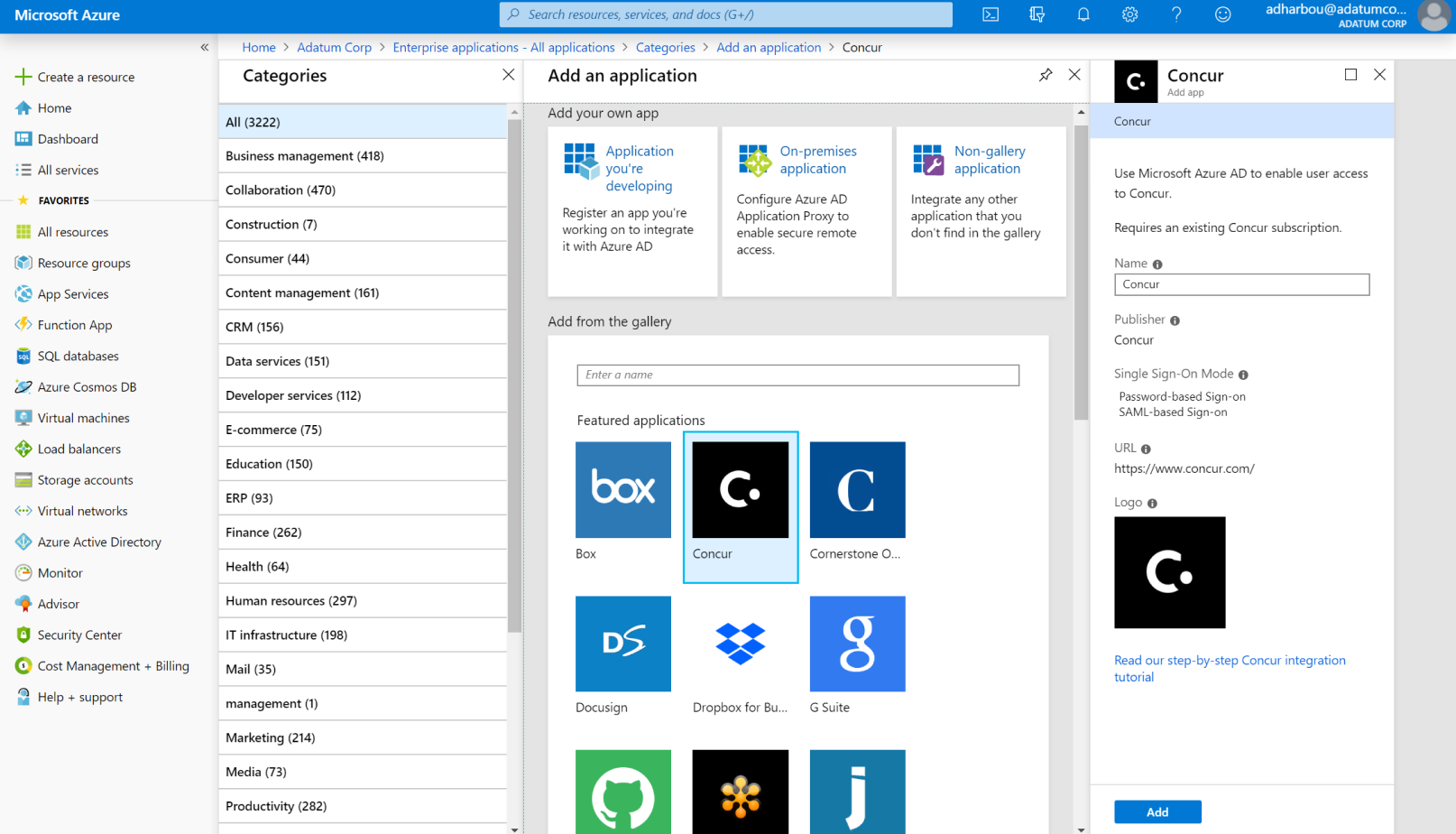
Inside your code (in your backend), you will need to make network requests to the IDaaS endpoints:
fetch("https://example.com/api/auth").then((res) => { if (res.authenticated === true) { const { userId, name, email } = res; }});Or, the IDaaS will provide you with a software development kit (SDK). All you have to do is to call the methods like IDaaS_login() and the SDK will do the job for you.
If you go with IDaaS, you should be given a platform where you can manage everything. One great benefit is that you do not need to manage a database and do not have to worry about security as those have been taken care of.
OAuth2, on the other hand, refers to a protocol for authorization (Note the difference from Authentication). Authorization in this context means giving applications access to your data. It is not a means of authentication, and some people often misunderstand it.
For example, Facebook and Google are two of the most popular implementations of OAuth2. Surfing the web, you may often these buttons below.

If I am building an app myself, I will need to have a database to store the mentioned user application. However, I can instead take the information directly from third-party services since users are likely to have accounts on such services and use it on the fly. When you authorize the application (where you click Sign in with...), the application has access to your name, email, and other information based on the scope of your authorization.
However, since this post is to go deep into the above methods, I will cut it short here.
Why not?
If I use one of the above methods, I depend on them.
If the IDaaS I use decides to close its services one day, I will be in the middle of a crisis since my user then cannot log in, and I lose all of their data. My application can be shut down. It does not make sense that I create my application but do not have any control of my userbase.
If I use Google and Facebook, I am giving away my user data to those giants, who will use it for monetization (and I am certain we hear enough about companies tracking/stalking our every step). What if they get into some ugly scandals, like Facebook and its Cambridge Analytica scandal. I will not feel so good since the users trust me to deliver a safe and friendly application.
What to know when building an authentication system
Before I start, I will need to warn you that this is not recommended to everyone. With a great authentication system, comes great responsibility. When the user signs into my system, they bet their data on me. If the system is misconfigured and gets hacked (leaked email, password, personal information), I will be blamed for all the troubles. It is not simply an "if (email is matched and password is also matched) give away all the information". We should be aware that even the most strongly built system (even from big tech companies) has vulnerabilities.
1. Deciding on a password hashing function
I wish I knew about hashing.


Hashing is a method that converts a piece of data into a unique unreadable string. The output of hashing depends on the algorithm being used. Two identical data will have the same hash if they use the same hashing algorithm (for example, SHA-1, MD5). If you want to learn about it, I have a link to the Wikipedia page for Cryptographic Hash Function.
What you need to know is that, is it not possible to reverse a cryptographic hash mathematically. If I know the input, I can get the hash of it. However, having the hash does not give me the input. This is how the password should be treated.
Imagine BadBoyX123 hacks your database and has access to the password of Vic, say it be noonecanguessmypassword123. However, the dangerous part is that Vic also uses noonecanguessmypassword123 for his bank account. The hacker then tries to use the password to log into aprettysecuredbank.com, and it just works. Vic now loses his money, and he is screaming at you from your front door.
However, if the password has been hashed, what BadBoyX123 sees is $2y$12$bk555TZzneTDOQPPcSOBZeutbukCi9JwtVBvjscrd7kczmHpVTBLm, the hashed password, he will never know about noonecanguessmypassword123. And of course, he cannot take the gibberish text above to log into aprettysecuredbank.com.
Below is how the password is hashed and checked.
When Vic signed up with the password noonecanguessmypassword123, it gets translated (using an algorithm) into and saved in the database as $2y$12$bk555TZzneTDOQPPcSOBZeutbukCi9JwtVBvjscrd7kczmHpVTBLm.
When Vic tries to sign in with the password noonecanguessmypassword123, it again gets translated (using the same algorithm) into $2y$12$bk555TZzneTDOQPPcSOBZeutbukCi9JwtVBvjscrd7kczmHpVTBLm and matched with the one in the database. If it matches, he is in.
As I say, the output of hashing depends on the algorithm being used. For example, with a different algorithm noonecanguessmypassword123 could have become $argon2i$v=19$m=1024,t=2,p=2$UzJSOFRnakRoRlNvRnltLw$0lpYLbJsc46HcAwDXMqkhVRpo1BGuF0QZxMSsSd2Kl0. Why different algorithms out there? Well, the reason is that nothing is perfect. Some hashes can be cracked, usually by brute-forcing (trying every possible combination). If the algorithm is weak, you are risked the password getting cracked.
Common password hashing algorithm includes:
- bcrypt
- scrypt
- argon2
Feel free to google "bcrypt vs scrypt vs argon2" to decide on the best one. The most popular one among them is bcrypt. However, I will suggest argon2 since it was the winner of the Password Hashing Competition. Also, some papers suggest ways to crack bcrypt, such as this. Often, however, it is not easy to crack a password hash anyway without invested systems (and when the algorithm is implemented correctly) so you can still use any algorithm you like.
2. Databases, NoSQL or SQL
I wished I knew well about databases, which took me a lot of time to decide.
To have an authentication system, we need to store users' login and passwords somewhere. When choosing a database, we are often presented with two options: Structured Query Language (SQL, also known as a relational database) and Not Only Structured Query Language (NoSQL, originally known as"non-SQL" or "non-relational").
One distinction between SQL and NoSQL would probably be how data is structured. We have a table structure in SQL and a key-value pair structure in NoSQL. However, what is worth knowing is the scalability, Flexibility & Security of each one.
Scalability
There are two terms when it comes to scalability: Vertically scale, and Horizontally scale. You can think of the vertical scale as stacking more things on top of one thing and the horizontal scale as placing more things next to each other.
SQL allows you to vertically scale by adding more power to existed machines (RAM, CPU). The reason is that SQL databases are designed to work by having the whole dataset in one node. If there are multiple tables, the tables need to join together as one for the data to make sense.
NoSQL, on the other hand, allows you to horizontally scale by adding more machines. The reason is that NoSQL databases are designed to be split across different nodes (sharding).
If the database is large, scaling SQL Database can be costly, and it might be cheaper to just add more machines in NoSQL. However, this is not completely true nowadays since SQL Database may be sharded just like NoSQL. Still, it will be complicated to do so.
Speed & Security
Another key difference between SQL and NoSQL is the data structure. SQL data is predefined. Once the data type is set, it cannot be changed. NoSQL data is flexible and can be changed in the future.
SQL databases are Atomicity, Consistency, Isolation, Durability (ACID) compliant. The properties guarantee that data in the database is always validated:
- A transaction, which is composed of multiple statements, should succeed (all statements succeed) or fail (one of the statements fails).
- Data types need to be consistent. All data written to the database need to be validated.
- Sequential and concurrent transactions should produce the same states.
- Data needs to be reliable: It should still be committed even in case of system failure.
On the other hand, NoSQL databases drop ACID in favor of speed. NoSQL data is very flexible since it has no constraints. Since my data is not validated, my database can risk accepting bad data. Therefore, I will need to write my validation.
This is a two-part series: Read the second part here.